artigos sobre linux - IBM
Esse é um achado! Vi este link no Linux From Scratch: http://www.ibm.com/developerworks/linux/.
É um repositório de informações sobre linux da IBM. Achei muito bacana!
Esse é um achado! Vi este link no Linux From Scratch: http://www.ibm.com/developerworks/linux/.
É um repositório de informações sobre linux da IBM. Achei muito bacana!
Venci o desafio lançado a mim mesmo! Consegui uma maneira rápida de desassemblar uma função e ver os opcodes em hexadecimal! E nada de grep+sed, apenas o bom e velho shell script. Aí vai a solução:
#!/bin/bashTá tá tá... não ficou lá muito elegante, mas é só pra quebrar um galho, né!
if [ $# -ne 2 ]; then
echo "Falta parametros!"
echo
echo "Uso: `basename $0` funcao programa"
echo
exit 1
fi
# a opcao -t do objdump mostra a tabela de simbolos do arquivo
# e eh lah que temos as informacoes sobre as funcoes do programa
# tais como endereco, tamanho, nome, etc...
# o grep procura a funcao que queremos na tabela de simbolos
LINHA=`objdump -t $2 | grep " $1$"` || {
echo "Erro!"
echo
echo "Nao existe a funcao \"$1\" no programa \"$2\""
echo
exit 1
}
# a variavel ENDERECO tem o endereco inicial e final da funcao
# mais infos sobre vetores em bash no meu texto de bashscripting
ENDERECO=(`echo $LINHA | cut -d' ' -f1,5`)
# a saida do objdump NAO coloca 0x no inicio dos numeros hexa
INICIO="0x${ENDERECO[0]}"
# o endereco final eh (inicio + tamanho_da_funcao)
# a conta eh feita dentro do $[ cifrao-colchetes ]
FIM="$[ $INICIO + 0x${ENDERECO[1]} ]"
# voilah! agora o golpe de misericordia:
objdump -j.text -d --start-address=$INICIO --stop-address=$FIM $2
Eu achava que o bash ignorava o setuid bit nele mesmo. Mas descobri na man page a opção -p. Faça testes e observe ;-)
Algumas vezes, depois de usar o ettercap por exemplo, temos que reativar o "IP Forwarding" do kernel. O seguinte comando faz isso:
# sysctl net.inet.ip.forwarding=1
Documento interessante, cheio de referências muito interessantes também: http://www.jpl.com.br/linux/ref_power2bash.pt_br.pdf.
Ótimo livro sobre os primeiros passos em programação assembly x86 para linux: http://savannah.nongnu.org/projects/pgubook
Essa eu aprendi na man page do gdb. Achei útil para ver o endereço e o tamanho das instruçoões.
O parâmetro "-batch" executa o gdb no modo execução de comandos em lote. E o parâmetro "-x file" é o arquivo onde está os comandos a serem executados.
Por exemplo: veja o seguinte arquivo chamado disassmain.
disassemble main
disassemble é o comando do gdb que desassembla uma função
Agora execute o seguinte comando (supondo um programa chamado prog):
$ gdb -batch -x disassmain prog
Observe o resultado e veja que maravilha! ;-)
Agora eu fiz um script muito simples, porém interessante, que recebe como parâmetros na linha de comando o nome da funcao a ser "desassemblada" e o nome do programa. Chamei-o carinhosamente de mdisasm (meleu's disassembler):
#!/bin/bash
TMPFILE=/tmp/mdisasm.$$ # este '$$' retorna o PID do script em execucaoif [ $# -ne 2 ]; then # $# eh o numero de argumentos (tem que ser 2)
echo
echo "uso: `basename $0` funcao programa
echo
exit 1
ficat << _EOF_ > $TMPFILE # abaixo daqui ateh _EOF_ vai para $TMPFILE
disassemble $1
_EOF_gdb -batch -x $TMPFILE $2
rm -f $TMPFILE
Isso é útil quando queremos ver o endereço de uma determinada instrução, seu tamanho e o seu mnemônico.
Agora para "desassemblar" uma única função e ver as instruções em hexadecimal (útil para escrita de shellcodes) eu ainda não achei uma solução. Ainda continuo usando 'objudump -d prog > arquivo.out' e depois lendo arquivo.out procurando a função desejada. Fica lançado um desafio pra mim mesmo. Queria uma solução simples, mas acho que terei que apelar para o grep+sed...
[Desafio vencido: http://mdicas.blogspot.com/2007/07/desassemblando-para-hexadecimal.html]
$ gcc -mpreferred-stack-boundary=2 prog.c -o progMacete aprendido no livro The Shellcoder's Handbook.
Link precioso para quem trabalha com o supervisório VXL: http://www.csiks.com/vxl/
Dica para OpenVMS. Nada a ver com Linux, UNIX, FreeBSD e muito menos Windows.
Essa eu aprendi em algum texto encontrado em http://www.kgbreport.com/dcl.html, só não me lembro qual.
Usar READ no lugar de INQUIRE para entrada de dados faz com que o dado entrado NÃO fique no buffer do RECALL (ou seta para cima). O READ também não converte a string entrada para maiúsculo como o INQUIRE faz. Estas características do READ são favoráveis em vários momentos.
Exemplo:
$ READ SYS$COMMAND SIMBOLO /PROMPT="Entre com o dado: "
$ INQUIRE I_STRING "INQUIRE PROMPT"
$ READ SYS$COMMAND R_STRING /PROMPT="READ PROMPT: "
$ WRITE SYS$OUTPUT "I_STRING: ",I_STRING
$ WRITE SYS$OUTPUT "R_STRING: ",R_STRING
Dica para OpenVMS. Nada a ver com Linux, UNIX, FreeBSD e muito menos Windows.
Isso e muitas outras coisas eu aprendi em http://www.kgbreport.com/dcl/198703.txt
Imprimir caracteres com altura dupla fica bem bonito! ;-) Veja o código:
$ ESC[0,32] = %X1B
$ ALTDC = ESC+"#3" ! parte de cima da string
$ ALTDB = ESC+"#4" ! parte de baixo da string
$ WRITE SYS$OUTPUT ALTDC,"Exemplo: meleu eh nerd!"
$ WRITE SYS$OUTPUT ALTDB,"Exemplo: meleu eh nerd!"
Dica para OpenVMS. Nada a ver com Linux, UNIX, FreeBSD e muito menos Windows.
Ainda não descobri um comando que limpa o terminal no OpenVMS. Um equivalente ao 'cls' no DOS ou um 'clear' nos shells do UNIX. Sendo assim eu costumo fazer a seguinte gambiarra:
$ CLS:==TYPE/PAGE NL:
Dica para OpenVMS. Nada a ver com Linux, UNIX, FreeBSD e muito menos Windows.
Para fazer atribuição bit-a-bit a um símbolo no DCL (variável do shell) utiliza-se o seguinte formato:
$ SIMBOLO[posicao_do_bit,numero_de_bits]=expressão
$ STRING[16,8]=90
$ ESC[0,32]=%x1B
Essa eu li em http://br.geocities.com/cesarakg/tips-shell-programming.html.
Quando executamos um arquivo que começa com o #! (chamado de hash-bang) o kernel lê o arquivo, vê o hash-bang, e continua a ler o resto da linha. Então ele pega o que ele encontrar nesta linha depois do hash-bang e executa tendo como parâmetro o próprio arquivo.
Vamos aos exemplos:
O arquivo abaixo chama-se hello.sh:
#!/bin/bash
# hello.sh: o famigerado "Hello World!"
echo "Hello World!"
prompt$ ./hello.sh
prompt$ /bin/bash hello.sh
#!/bin/cat
vi unix editor
man manual pages
sh Bourne Shell
ksh Korn Shell
csh C Shell
bash Bourne Again Shell
Link para o Linux From Scratch em português em diversos formatos: http://codigolivre.org.br/frs/?group_id=453
Boa leitura.
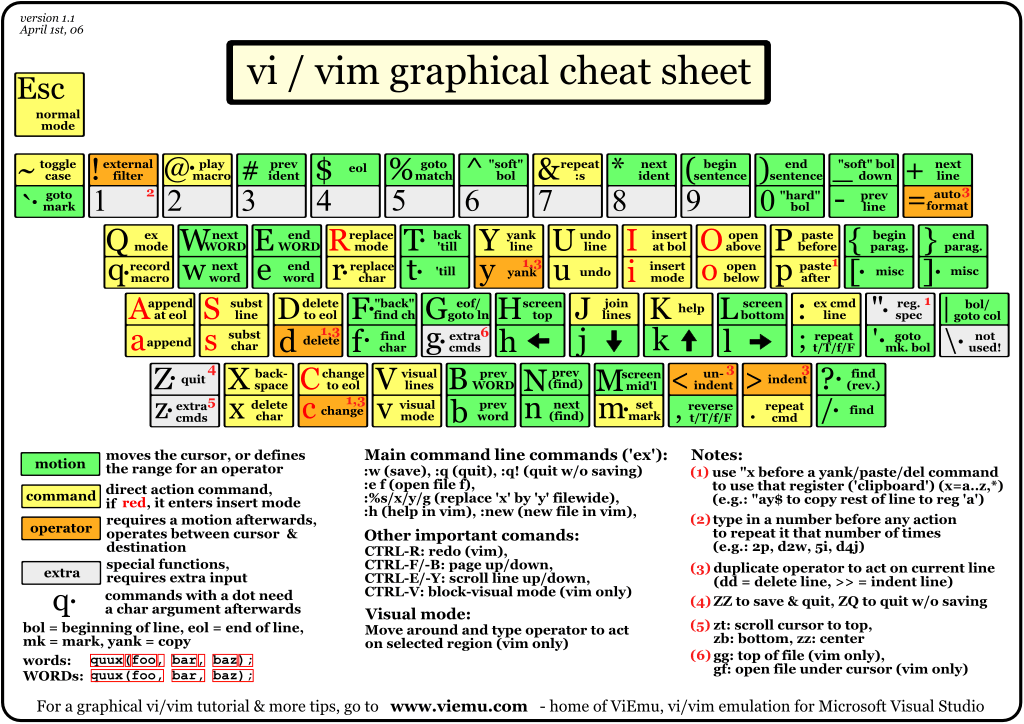
O vim é o meu editor favorito. E para programar em C é o melhor que já usei. Aqui vai alguns macetes úteis que foram retirados do C editing with VIM HOWTO.
1. Movendo-se pelo texto
{ - volta um parágrafo
} - avança um parágrafo
][ - avança para o próximo } que estiver na primeira coluna
[] - volta para o mais próximo } que estiver na primeira coluna
% - alterna o (, {, ou [ que casa com seu respectivo ), }, ou ].
2. Saltando para posições aleatórias
+ ctags:
Resumo:
ctags *.c - cria o arquivo tags a ser usado pelo vim
CTRL+] - pula para a declaração do identificador (função ou var)
CTRL+T - pula para a posição que estava quando chamou CTRL+]
Descrição:
Primeiro deve-se usar o programa ctags nos arquivos .c para então
chamar o vim. Por exemplo:
[prompt]$ ctags *.c
Este comando criará um arquivo chamado tags no diretório corrente.
Agora quando chamar o vim basta teclar CTRL+] para ir para a declaração de
um identificador, e CTRL+T para voltar de onde chamou.
+ marcadores:
m' - marca uma posição
'' - vai para a posição marcada
m? - marca a posição ? que pode ser A-Z e a-z
'? - vai para a posição marcada com ?
3. Auto-completando palavras
CTRL+P - procura a palavra e mostra as opções (inclusive nos includes)
CTRL+N - idem acima só que no sentido contrário
4. Auto-formatação
:set textwidth=75 - texto com 75 colunas
:set cindent - indentação automática
5. Corrigindo rapidamente
:set makeprg=make\ %:r - configura :make para 'make arquivo_sem_extensao'
:make - executa o que está configurado em makeprg
:cn e :cN - vai para o erro (n vai, N volta)
6. Outros itens adicionados por mim
:map <F9> :w<CR>:make<CR> - <F9> salva e compila
:map <F10> :w<CR>:make<CR>:!./%:r - <F10> salva, compila e espera argumentos
Estava eu pensando em o que fazer com algumas máquinas antigas que tenho aqui e resolvi concentrar memória em uma máquina com um Pentium de 233 MHz para utilizá-lo como "servidor" de internet utilizando o FreeBSD com NAT ativado. Mas antes de começar a correr atrás de como configurar e ajeitar toda minha rede e essas coisas tive que procurar a resposta para a seguinte pergunta: como me conectar a velox utilizando FreeBSD?
Encontrei a resposta em http://www.free.bsd.com.br/noticia.php3?CAD=1&NOT=82. Mas como podemos observar no título deste artigo, ele foi escrito em 2001. Época em que você se conectava na velox com o numero do seu telefone como login e senha e a autenticação era feita numa página chamada de veloxzone.
Acontece que hoje em dia isso não é mais necessário, você já se conecta com o seu login e senha do provedor de acesso e não precisa de qualquer outra autenticação. Portanto, várias etapas explicadas no artigo mencionado não são mais necessárias nos dias de hoje.
Pois bem. Estava eu lendo este tal artigo e logo no comecinho dele o autor nos sugere um arquivo /etc/ppp.conf a ser utilizado para estabelecer a conexão com a Velox e depois ele mostra um script que ele fez para automatizar a autenticação no veloxzone. Quando eu fui testar o ppp com este ppp.conf observei que dava pra conectar tranquilamente sem precisar de nenhuma outra configuração, devido a alterações por parte da telemar. Hoje em dia a autenticação é feita somente no ato da conexão, não existe mais a autenticação via veloxzone.
Sendo assim, pegue ppp.conf encontrado em http://www.isec.com.br/velox/ppp.conf e siga as instruções mencionadas nos comentários do arquivo. Sendo que no final do arquivo temos o seguinte:
set authname 715557777
set authkey 715557777
set authname nome.do.usuario@provedor.com.br
set authkey minha.senha.de.conexao
# ppp -ddial
OBSERVAÇÕES: Este procedimento foi retirado do livro "Compartilhe a Internet usando FreeBSD+Squid". O que está descrito aqui somente configura o kernel para realizar NAT. Para compartilhar a conexão com sua rede interna são necessárias muitas outras coisas não descritas aqui.
Fazer um backup da configuração original (usualmente GENERIC)
# cd /usr/src/sys/i386/conf/
# cp -p GENERIC MEUKERN
# define a politica aberta do firewall
options IPFIREWALL_DEFAULT_TO_ACCEPT
# ativa ipfw
options IPFIREWALL
# ativa log do ipfw atraves do syslog
options IPFIREWALL_VERBOSE
options IPFIREWALL_VERBOSE_LIMIT=100
# ativa NAT
options IPFIREWALL_FORWARD
#ativa o redirecionamento de porta atraves do socket "divert"
options IPDIVERT
# cd /usr/src
# make buildkernel KERNCONF=MEUKERN
# make isntallkern KERNCONF=MEUKERN
firewall_enable="YES"
firewall_type="OPEN"
natd_enable="YES"
natd_interface="dc0"
natd_flags=""
# shutdown -r now
{kind=link}